
Milivault
By Keenan Nilson
A Data Platform Tracking and Sorting 350,000+ Military Antiques Across 100+ Dealer Sites
Tech at a glance

350k+ items • 100+ dealers
67k labeled items
How does the site function?
Hosted on Render, connected to my AWS services.
Frontend: Django + HTML/CSS.
How is the data hosted?
Product data in AWS RDS (PostgreSQL).
Images in AWS S3.
Live site on Render + Django.

~80–90% classified locally

~80% cost & time reduction
How is the data collected?
Custom Python scraper on AWS EC2.
350k+ items, 100+ dealers, 67k labeled items.
~80–90% classified locally, ~80% cost & time reduction.
10-minute checks.
How is the data kept fresh?
Lightweight job every 10 minutes + full refresh every 12 hours.
Keeps data current without overloading source sites or servers.
10-minute checks • 12-hour full refresh
How is the data classified?
Trained a scikit-learn model using a militaria taxonomy.
Seeded with 67,000 hand-labeled products (Streamlit tool).
Low-confidence cases go to OpenAI API; unclear results flagged for human review.
Stack: Python, Django, AWS (RDS, S3, EC2), Render, Streamlit, scikit-learn, OpenAI API.
Main Objective
Build a scalable platform to collect, clean, classify, and host militaria product data at scale, laying the foundation for future market insights.
Core Achievements
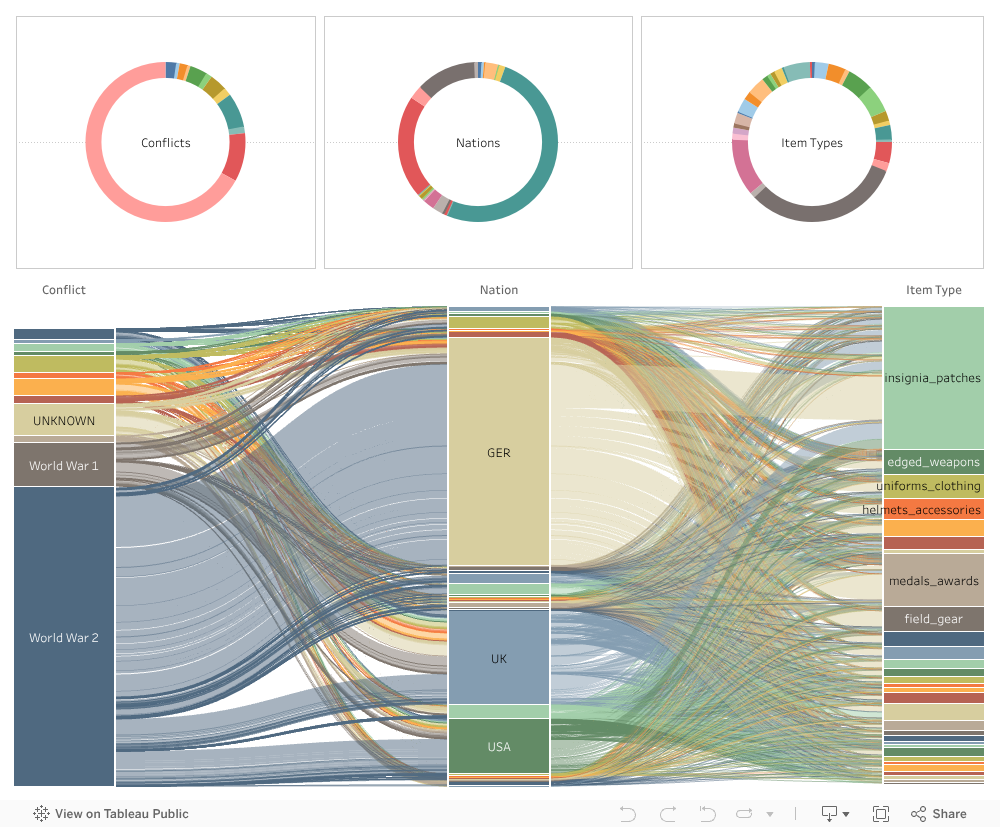
350k+ products tracked across 100+ dealer sites, each with 50+ fields and images.
Scraper framework (Python + AWS EC2) with JSON configs for flexible site integration.
Database & hosting – PostgreSQL (AWS RDS) + S3 for images, served via Django + Render.
Classification pipeline – Custom ML model trained on 67k labeled items, with OpenAI fallback + Streamlit review app.
The Main Components
-

1. Gather the Data
Custom Python scrapers with JSON configs pull listings from 100+ dealer sites. Each record is cleaned, deduplicated, and enriched (hidden prices, availability, normalized fields). The data is stored in AWS RDS with product images in S3.
-

2. Classify the Data
I trained a scikit-learn model on 67k manually labeled items (via a Streamlit app) to classify products into a taxonomy I designed. When confidence is low, products are sent to OpenAI for backup classification. Any remaining edge cases are flagged for human review.
-

3. Case Study: WW2 Helmets
WWII helmets often look nearly identical, yet their prices can vary dramatically. This raises an important question: what actually drives these differences in the militaria market?
-

4. Case Study: A Medal's Worth?
Collector markets often appear unpredictable. Two items that look nearly identical may sell for very different prices, leaving both buyers and sellers uncertain about what truly drives value.
-

5. Present the Data
The cleaned and classified dataset powers a Django site (milivault.com) and Streamlit tools. Users can search, filter, and confirm classifications, making the data both useful and transparent.

Why I built this
I have always had a deep love for my local antique shop, which was unique in that it exclusively sold military antiques. The shop also had its own museum and a vibrant, one-of-a-kind atmosphere. I volunteered there every weekend for years, learning about the history behind each piece and connecting with the militaria community. Unfortunately, the shop is no longer in business, but that doesn’t mean my passion for antiques has faded. While I may now explore antiques and follow trends in a less traditional way, my love for the craft and my appreciation for the stories these objects hold remains strong.