
Classify the Data
Problem: Messy & Inconsistent Categories
None of the dealer websites I scrape actually provide structured categories for item type, conflict, or nation. Every site invents its own taxonomy, and most don’t even follow it consistently. What one dealer calls a medal, another calls insignia, and a third throws into “personal items.” It’s unreliable to the point of being useless.
On top of that, titles and descriptions vary wildly:
“Rare original German Children’s Toy Helmet” (Toys) vs. “WW2 German M35 Army Double Decal Combat Helmet – Hauptmann Named” (Helmets & Accessories).
“WW2 German Army Officer Postcard Portrait” (Photos & Albums) vs. “Ritterkreuzträger Postcard Major Niemack” (Postcards).
“DEACTIVATED MOVING BOLT STEN MKII SMG” (Small Arms) vs. “DENIX WW2 STEN MK.II SMG Replica” (Reproduction).
Some descriptions run for paragraphs, while others are completely blank. Many dealers post in German, Japanese, Dutch, or French, making things even less standardized. And then there are edge cases:
Is a WW1 helmet reissued in WW2 a WW1 artifact or a WW2 artifact?
Do you classify ammo crates with ammunition or with vehicles?
Do you file a cap badge under headgear or under insignia (the correct choice is insignia — collectors don’t want badges lumped into headgear)?
These inconsistencies make any kind of large-scale analysis impossible. You can’t chart prices by conflict if half the helmets are mislabeled. You can’t compare marketplaces if one dealer’s “medals” includes propaganda tinnies, while another dealer’s doesn’t.
The result: raw dealer data is too messy and inconsistent to use directly. To make it meaningful, I needed to design my own strict taxonomy and build models that could enforce it reliably across 350k+ products.


The AI classifier placed this reproduction U.S. crusher cap (image on the left) under Headwear, since it looks like a hat. But in our taxonomy, reproductions are always prioritized into the Reproduction category regardless of type. The ML model correctly captured that nuance, while the AI model missed it — highlighting how AI struggles with prioritization rules and taxonomy intricacies.
The AI classifier placed this decorated shell casing under Ordnance because of its original form. However, in our taxonomy, trench art and other modified items belong in the Art category. The ML model recognized this nuance correctly, while the AI model failed — showing how AI often struggles with contextual rules and the subtleties of militaria classification.
Solution: A Hybrid Classification Pipeline
Dealer categories were too messy to use, so I built my own system from the ground up. I designed a strict taxonomy in JSON (supergroups → item types → nations → conflicts), inspired by trusted dealers like Collector’s Guild and Petaluma Military Antiques and Museum, plus my own knowledge as a collector. The rules are tight: belts and buckles never slip into field gear, insignia never gets lumped into headwear, and helmets always get handled separately from goggles. By enforcing clear boundaries, the system avoids the arbitrary overlaps that plague dealer sites.
With that taxonomy in place, I built a hybrid ML + AI classification pipeline:
Machine Learning (first pass):
A scikit-learn model (TF-IDF word+char n-grams → calibrated logistic regression) trained on 67,000 manually labeled products. I labeled these myself using a Streamlit app I built that let me confirm predictions in bulk, override mistakes, and keep a growing clean dataset in PostgreSQL.The model uses per-class thresholds stored in JSON, so I can tune precision/recall tradeoffs differently for helmets vs medals, for example.
In practice, the model now handles the majority of classifications confidently on its own.
OpenAI Fallback (only when needed):
When the model isn’t confident enough, I call OpenAI with a structured, compact prompt. To cut costs, I first narrow by supergroup, then only send the categories inside that group. This trick reduces token usage by ~60–90% depending on category size. At this stage, I also attach the product image so GPT has a visual reference.Human-in-the-loop:
Anything unclear can be validated in my Streamlit app. I used this both to train the original dataset (67k products) and to validate edge cases the models struggled with later.
Results so far:
~80–90% of items are classified locally by the ML model, with only the hard edge cases escalated to OpenAI.
At practical thresholds (~85%), the item type model achieves <2% error rate while covering over half the dataset.
What would take a human weeks to classify by hand now happens in minutes per batch.
OpenAI usage is kept minimal, cutting token costs by ~60–90%.
Hybrid Classification Pipeline
Input

Raw product data scraped from dealer sites.
ML Model (74%)
67k training samples, tuned thresholds. Handles ~80–90% of classifications.
AI Fallback (20%)
Only used when ML confidence < threshold. Saves 60–90% of token costs.
Human Review (6%)
Manual overrides + training feedback loop.
Results: Item Type Model in Production
The item type classifier is now fully integrated into my pipeline and running in production across 350,000+ products from 100+ dealer sites. It works fast, stays cheap, and produces reliable structured categories at scale.
Dataset & Scale
Trained on 67,000 manually labeled products (validated one-by-one in my Streamlit tool).
Now classifies hundreds of thousands of listings automatically as they’re scraped.
Dataset covers everything from helmets and uniforms to propaganda postcards.
Performance Metrics
At practical thresholds (~0.85), the model achieves under 2% error rate while still covering over half of items.
With looser thresholds, coverage exceeds 90% at ~5% error.
Thresholds are per-class, so I can tune precision differently for tricky categories (helmets, insignia) versus clearer ones (medals, edged weapons).
Efficiency & Cost Savings
Supergroup narrowing reduces GPT token usage by ~60–90%, depending on category size.
Overall OpenAI spend is a fraction of what it would be if GPT classified everything.
My custom ML model confidently auto-classified ~74% of 352k products, leaving only 20% for AI fallback and 6% for human review. This reduced AI API costs dramatically, minimized human labor, and ensured that the hardest edge cases were flagged for review rather than misclassified.

Confusion Matrix (Item Type Classifier)
Trained on 67k labeled products, the model achieves <2% error at practical thresholds, with strong accuracy in clear categories (medals, weapons) and expected overlap in tricky ones (helmets, insignia).

By optimizing prompts, streamlining API calls, and introducing a custom machine learning model, I reduced both cost and processing time by ~80%. What once cost ~$400 a year and required nearly 7 hours of compute now costs ~$80 and takes less than 1.5 hours.
Impact
What once seemed impossible by hand — classifying hundreds of thousands of inconsistent product listings — is now largely automatic, consistent, and auditable.
Right now the system focuses on item type classification, with each prediction stored alongside the model version, thresholds applied, and confidence scores, so every decision can be traced and reproduced later.
This already delivers a clean, trustworthy dataset for analysis, market insights, and front-end applications — and because nation and conflict models aren’t yet included, the cost and time savings will grow even further once those are added.
In Progress: Nation & Conflict Models
After proving the pipeline with item type classification, I extended the same approach to nation and conflict models. These are still in development, but the early results already show promising patterns.
Nation Model
Trained on tens of thousands of labeled examples covering 30+ countries.
Performs strongly for nations with abundant data (Germany, USA, UK, Japan), with accuracy often 90%+.
Smaller nations (e.g., Ireland, South Africa, Czechoslovakia) show weaker accuracy due to limited samples — an expected tradeoff that improves as I gather more labeled data.
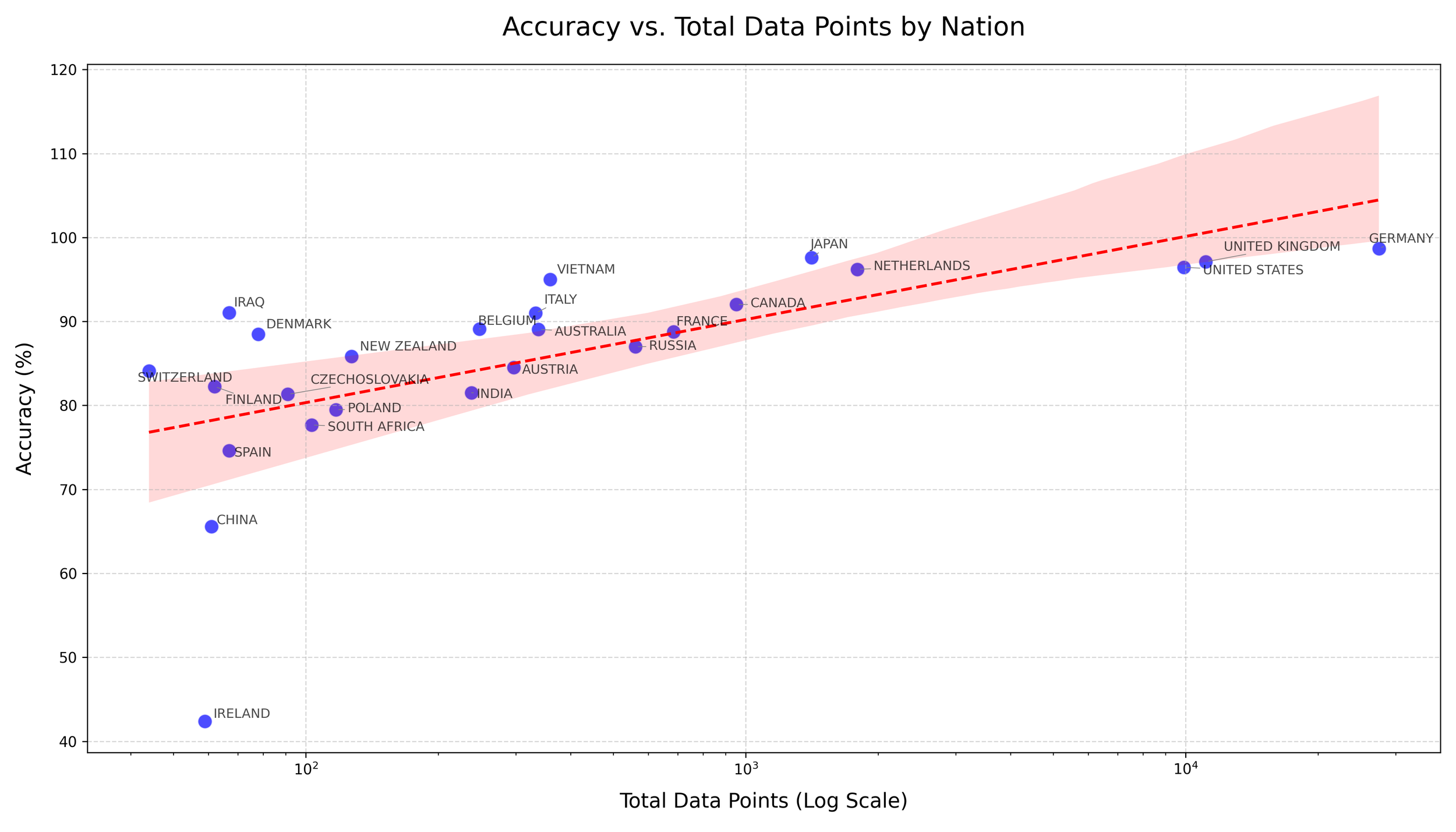
Accuracy by Nation
Accuracy improves with dataset size; most major nations achieve 90%+, with smaller sets (e.g., Ireland, China, Spain) showing more variance.

Confusion Matrix (Item Type Classifier)
Model delivers <2% error at practical thresholds, with strong separation on clear categories (medals, weapons) and expected overlap on trickier ones (helmets, insignia).

Distribution of Accuracy
Coverage is highly concentrated: >94% of data falls in the 90–100% accuracy range, confirming overall reliability.
Conflict Model
Covers Pre-19th Century through Modern conflicts (WW1, WW2, Cold War, Vietnam, etc.).
Larger conflicts like WW2 and WW1 already perform above 80–90% accuracy.
Smaller or more ambiguous categories (Pre-WW1, Post-WW2, Interwar) are weaker — again tied directly to dataset imbalance.

Accuracy by Conflict Size
Accuracy rises with more data; well-represented conflicts outperform smaller or less distinct ones.

Confusion Matrix (Conflict Model)
Larger conflicts (WW2, WW1) reach 80–90% accuracy, while smaller/ambiguous ones (Pre-WW1, Interwar, Post-WW2) show weaker results due to dataset imbalance.

Distribution of Accuracy
Most data (66%) sits in the 90–100% range, confirming strong reliability at scale.
Takeaways
Data volume directly correlates with accuracy — already visible in the nation and conflict experiments.
The chart to the right shows coverage vs. accuracy for each item type, with bubble size reflecting each category’s weighted contribution. Categories like insignia and medals dominate coverage and achieve high accuracy, meaning the model delivers the most value where it matters most. Smaller categories, while less impactful, reveal where additional labeling could further close accuracy gaps.
With continued labeling and dataset balancing, I expect nation and conflict models to reach the same reliability as item type. Even now, results show that structured classification is both feasible and scalable, bringing the system closer to a fully taxonomy-driven dataset.

Accuracy vs. Coverage (Item Types)
High-impact categories (insignia, medals) combine broad coverage with high accuracy, while smaller groups expose gaps where extra labeling could boost performance.
Next: Case Study WW2 Helmets
Using the data I collected, I ran a focused case study on WWII helmets to understand what drives price differences.
By analyzing how certain words and phrases in listings relate to price, I uncovered patterns that explain why some helmets are worth more — even when they seem similar at first glance.