
Presenting the Data
Challenge
A clean, classified dataset isn’t useful unless people can interact with it. I needed a way to turn raw militaria data into a product that both I and other collectors could actually use — a site where you can search, filter, and compare items across 100+ dealers in one place.
Solution: A Full Web Application (Django + Render)
I built a Django-based application, hosted on Render, backed by PostgreSQL on AWS RDS and images in S3. The site currently makes 350,000+ militaria products searchable in seconds.
Key features:
Search & Filter: Products can be filtered by conflict, nation, and item type or queried directly by keyword.
User Accounts: Visitors can register, save products, and build their own collections.
AI-Assisted Item Creation: Users can add their own items just by writing a description (e.g. “Purchased from vet’s estate, 82nd Airborne helmet, Normandy”). The system parses the text and fills in structured fields automatically.
Product Comparison (in progress): A side-by-side comparison tool for evaluating multiple items at once.
Scalability: Optimized queries and caching ensure that browsing stays fast even at scale.

Selecting a Conflict. Here we select World War One.

Selecting a nation. Here we select Hungary.
Finally we select a item type. Here we select Medals & Awards.

Now you can see all the products that fall into the categories you selected. We will select the first product.
How to Read a Product Page
Dealer Logo – Source site (here: Aberdeen Medals).
Title – Original dealer title, kept intact.
Price – Shown in dealer’s currency.
Availability – Updated automatically (Available/Sold).
Structured Metadata – Conflict, Nation, Item Type, Source Site, Product ID, Currency.
Shipping Info – Location when available.
View on Original Site – Opens the dealer’s product page.
Save – Add to your Milivault collection.
Description – Dealer text, cleaned and standardized.

Supporting Tools (Streamlit)
Alongside the site, I built internal tools in Streamlit to keep the dataset clean and usable:
Labeling Tool: A batch-confirm interface for quickly validating or overriding ML/OpenAI classifications.
SQL Explorer: A lightweight dashboard for querying and validating trends in the data.
These tools aren’t public-facing yet, but they show I can design internal ops tools as well as external products.
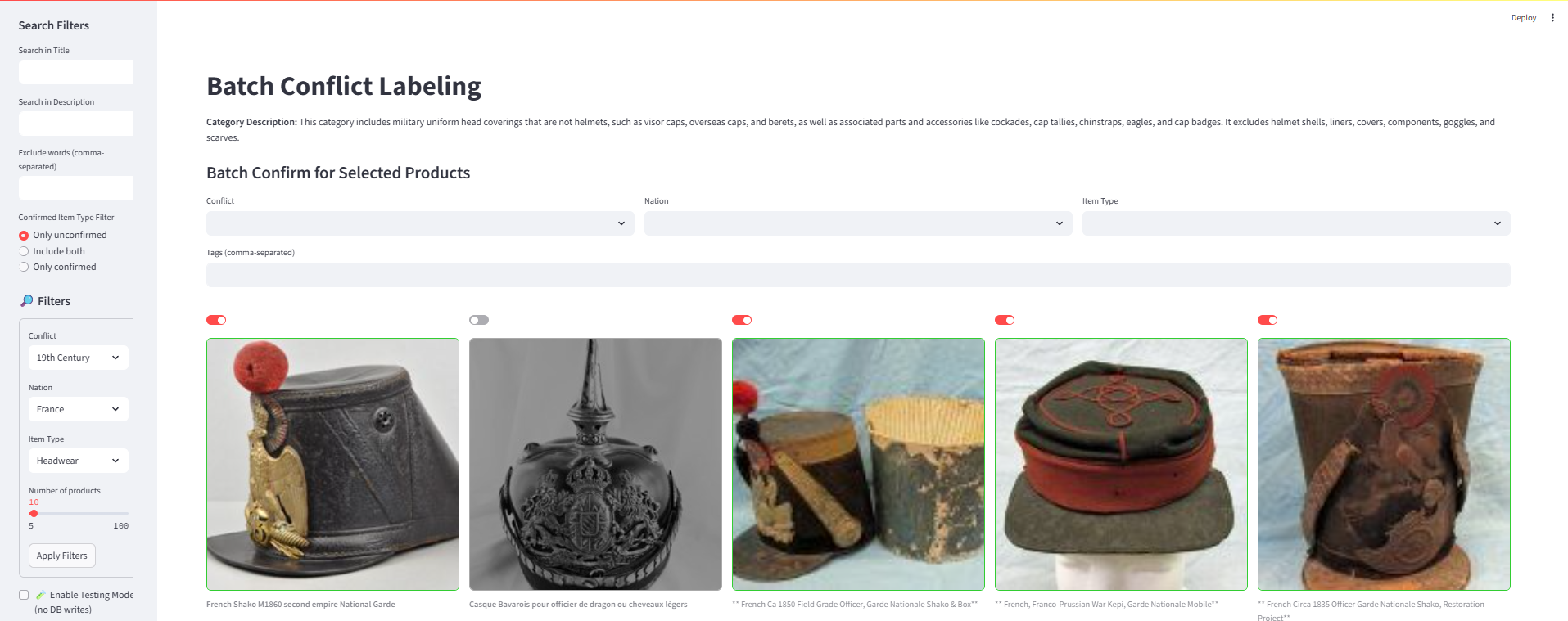
This Streamlit tool lets me validate products in bulk. Here, I’m confirming that these items belong to 19th Century, France, Headwear. The second product is actually a helmet, so I leave it unselected. With one action, I can batch-confirm the rest — updating the user_confirmed column in PostgreSQL. This human-in-the-loop workflow is what keeps 350,000+ classifications accurate while still scaling efficiently.
Results
A fully functional end-to-end system: from scraping to ML to a usable web application.
Hundreds of thousands of products pre-classified and searchable in one place.
Fast, responsive filtering across 100+ dealer sites — something no collector could do manually.
AI features integrated into both data ingestion (classification pipeline) and user input (AI-assisted item creation).
Early insights already emerging — e.g., analysis of helmets shows that sales platform is the strongest predictor of price.
Why it matters
This section closes the loop: I can take messy, unstructured dealer listings and turn them into a production-grade application. For a prospective employer, it demonstrates:
Full-stack capability: Django + PostgreSQL + AWS + Render.
Data engineering: handling 350k+ records with real-time search and filter.
ML/AI integration: hybrid classification pipeline + AI-assisted user workflows.
Product sense: building something real people could use, not just backend scripts.

Conclusion
I turned messy listings from 100+ independent dealers into a production data product: 350k+ items scraped, cleaned, classified, and searchable in seconds.
Milivault proves end-to-end execution: data collection (Python/AWS), model-driven classification (scikit-learn first pass, OpenAI fallback, human review), a reproducible data layer (PostgreSQL + history), and a usable application (Django on Render). The pipeline achieves ~80–90% local classifications, cuts cost/time by ~80%, and keeps data fresh on a 10-minute/12-hour cadence.
On top of the platform, I delivered market insights:
Helmets: price is driven most by dealer, completeness, decals, and scarcity (paratrooper M38 as the standout outlier).
Medals: tier/variant sets the baseline (EK1 > EK2), scarcity raises the curve, and boxes/documents add value mainly for rarer pieces; maker effects matter, condition less than collectors think.
Why this matters: Milivault turns an unruly niche market into structured, explainable data—useful for collectors (alerts/valuations), dealers (benchmarking), and analysts (pricing indices & trends). It’s not a demo; it’s a maintainable system with auditability, versioned models, and clear paths to product features.
What’s Next
Ship more models: move Nation and Conflict classifiers to production with active learning.
Pricing analytics: dealer-normalized price index, watchlists, and alerts for new/underpriced items.
User features: saved searches, collection tracking, “similar items” from text+image signals.
Data access: read-only API + curated monthly snapshots for researchers.